
 IEEE
IEEEA Reliable Data Loss Aware Algorithm for Fog-IoT Networks
Abstract
This paper considers a two-tier approach for the classification of user-generated data, where low-complexity decision algorithms are available on mobile devices, and a better assessment can be performed on a shared edge server to which the samples can be offloaded. While an overall accurate classification can be achieved by either massive offloading to the edge server alone or performing a computationally intense domain partitioning for local evaluation, both these solutions taken individually are excessively demanding. Importantly, the former strategy achieves higher accuracy, yet is very bandwidth-consuming, while the latter results in lower accuracy while reducing bandwidth usage. To cope with these challenges, the paper takes a quantitative stance to investigate the benefit of combining these two strategies, i.e., performing most of the evaluations with a local decision over constrained domains, while at the same time offloading to the edge server a small fraction of the samples for which the classification is expected to be less accurate. If properly harmonized, such an approach is shown to lead to a sharp increase in classification accuracy, with overall limited resource usage, which makes it suitable for practical implementations.
Motivations
-
Simplification or compression of the ML models to account for the constraints of the mobile devices (MDs).
-
Offloading the computing tasks to more powerful devices located at the network edge.
Contributions
-
A combined technique is developed for domain-constrained classification with proper exploitation of the edge computing architecture.
-
The performance of using local classifiers with properly trained domains versus offloading to the ESs is investigated from a quantitative standpoint, and the total benefit that can be achieved by combining the two techniques is evaluated.
-
The role of a proper selection of the samples to offload is discussed, where maximal accuracy of the classification is sought and compared with a simple random selection.
-
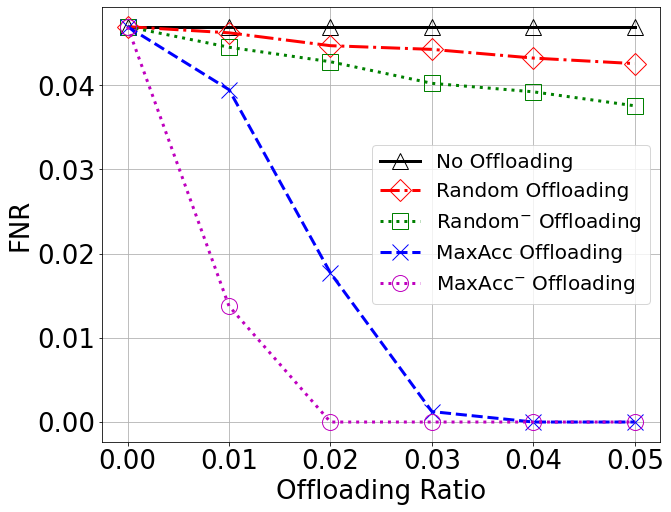
The option to minimize false negative rates is investigated as opposed to improving the accuracy of the entire classification, which can be useful for certain specific applications.
-
Importantly, the proposed domain-constrained method is different from existing methods in the literature, which mostly rely on a general domain of the dataset with model simplification. Instead, our technique focuses on local domains to build lightweight classifiers.
Results
Accuracy
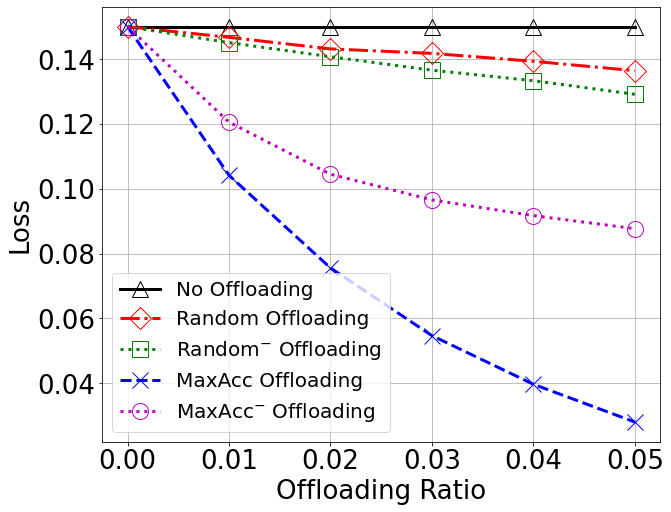
Accuracy vs Offloading Ratio
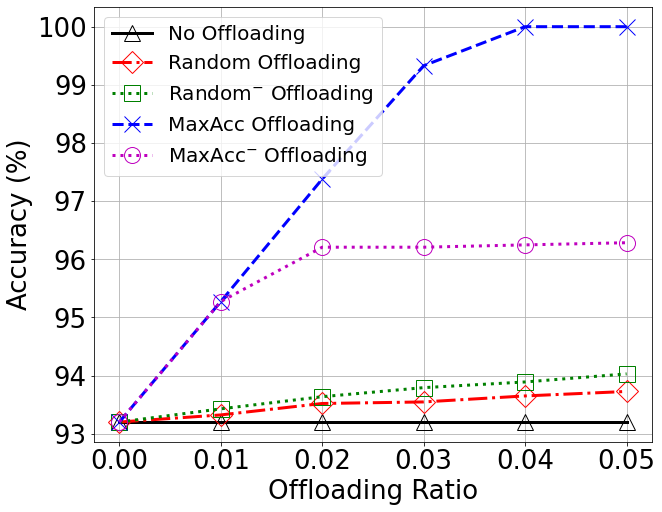
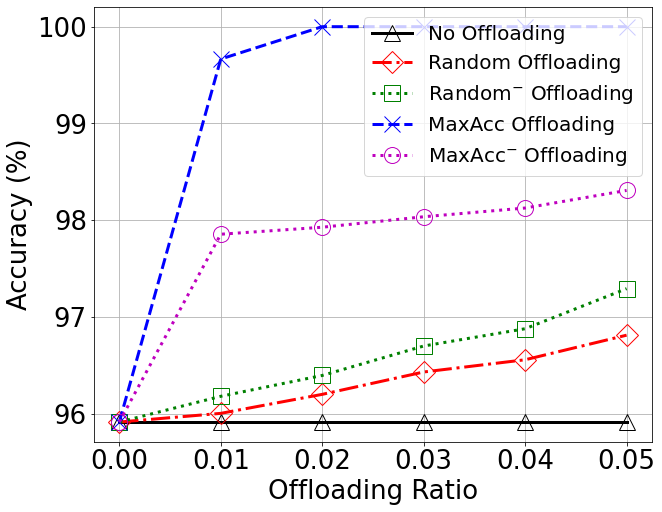
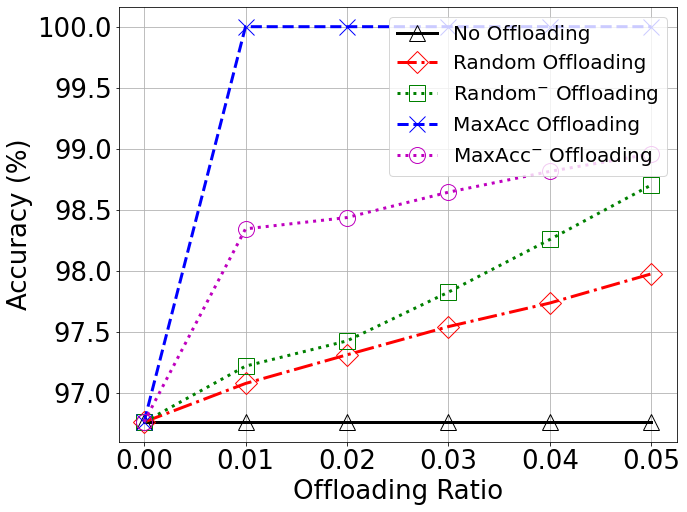
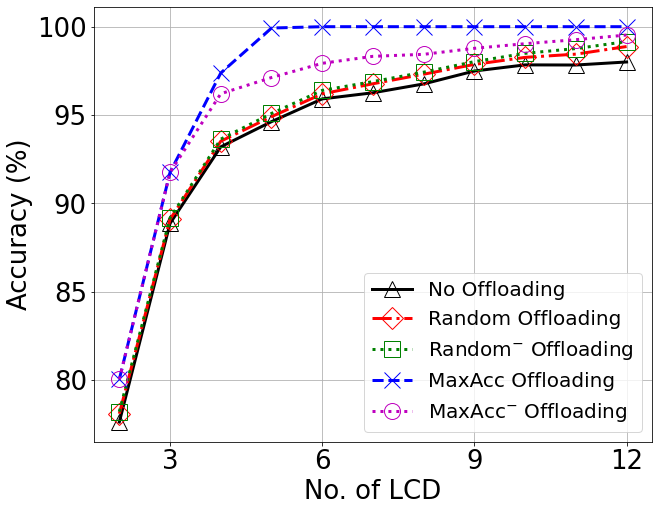
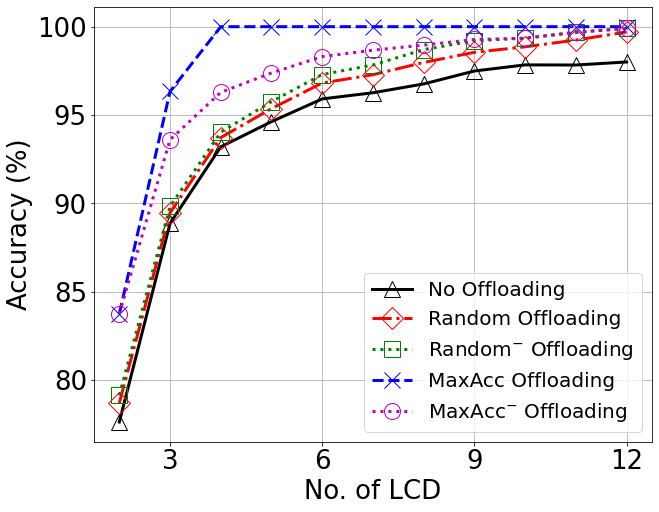
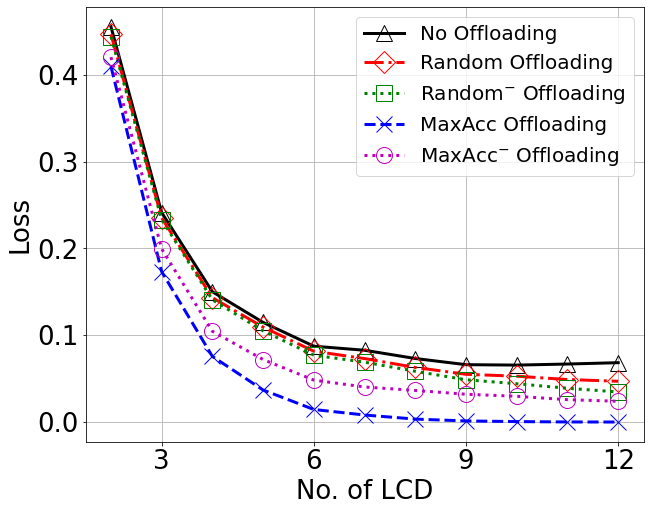
Accuracy vs Number of Local Classification Domains (LCDs)
Loss
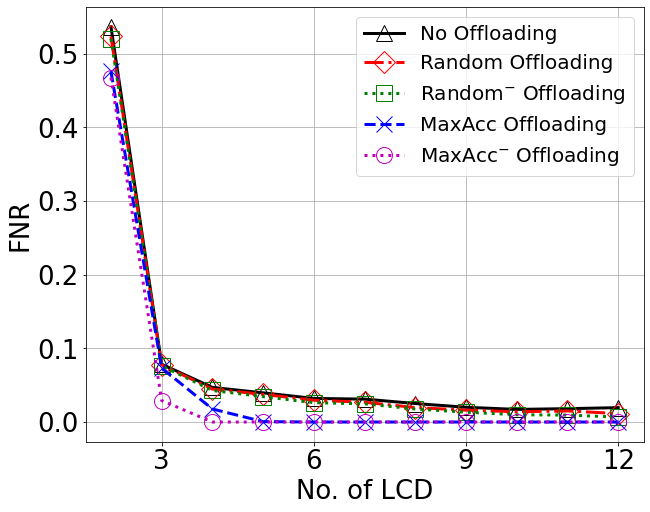
False Negative Ratio (FNR)
Conclusion
A two-tier architecture was investigated for data classification in IoT scenarios, where both individual devices and the reference ES have decision capabilities, but with different levels of accuracy. A harmonized approach was proposed that combines offloading to the ES of the most critical data, while at the same time adopting a domain classification on the majority of the data for local processing at the MDs. The resulting performance was analyzed and quantitatively showed that the two proposed policies are able to complement each other, therefore leading to a near-100% accuracy with limited offloading and a reasonable choice of the local classification domains. This validates the option of such an architecture for efficient decision-making in data-intensive contexts.