
 IEEE
IEEEOnline Domain Adaptive Classification for Mobile-to-Edge Computing
Abstract
A key challenge of today’s systems is the mismatch between the high computational demands of modern neural network models for data analysis and the severely limited resources of mobile devices. Existing solutions focus on model simplification and task offloading to compute-capable edge servers. The former often leads to performance degradation, whereas the latter requires the transfer of information-rich signals and is subject to the impairments of wireless channels. To address these issues, a framework that establishes a novel form of collaboration between mobile devices and edge servers is proposed herein. The core idea is to deploy lightweight models on mobile devices that are intelligently updated to match the current, and local, distribution of the samples being observed. The framework develops the temporal patterns of the samples to determine the optimal model update policy, as well as channel resources allocated to the mobile users. The performance of the proposed framework is evaluated via extensive experiments with both synthetic and real-world datasets.
Motivations
-
Offloading data to the edge server (ES) is inconvenient as it may clog a constrained communication channel and misuse a powerful computational resource, whereas a simpler classifier (albeit tailored to the specific domain) would suffice for most of the samples.
-
The limitations of a local classifier available at an mobile device (MD) prevent it from reaching high accuracy as well as performing a proper domain adaptation in the first place.
Contributions
-
A two-tier architecture is proposed that enables adaptive online retraining by leveraging the ES and MDs collaboratively. ES assists MDs by training lightweight classifiers using periodically estimated distribution parameters, turning the domain adaptation and online learning challenges into mutually supportive tasks.
-
Instead of relying on full data offloading, the framework minimizes raw data transmission by offloading only critical samples. This reduces network congestion and optimizes the use of limited communication bandwidth between MDs and the ES.
-
The framework delivers domain-specific, low-complexity classifiers tailored to each MD’s local data distribution, enabling real-time adaptation in resource-constrained settings. Its effectiveness is quantified through a detailed analysis of the tradeoff between classification accuracy and data offloading, along with a dynamic performance assessment under domain drift conditions.
Results for Synthetic Dataset
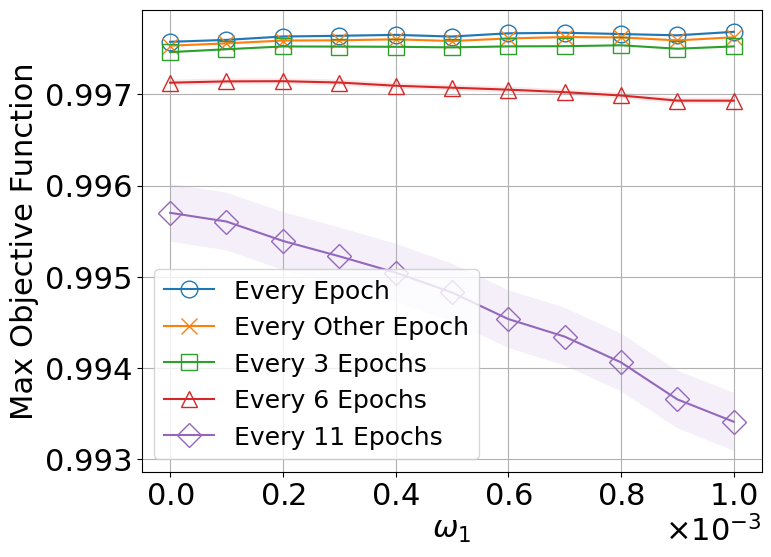
Accuracy: Due to variations in data domains, prediction accuracy is influenced by both the fraction of data offloaded to the edge server (ES) and the number of local adaptation domains (LADs) used in the local online domain-constrained classification. To capture this relationship, we define an objective function that depends on both the offloading fraction and the number of LADs. The results imply that by widening the range of the randomness for γ1, the local classification domain (LCD) is more likely to move back and forth and with a faster shift speed. This increases the inefficiency of the current model for the classification of the samples. Thus, the model might need to be updated. However, the delay in updating the model decreases the probability of choosing the most adaptive model. As such, more samples must be offloaded to the ES for classification.
Results for Real-world Dataset (UNITE)
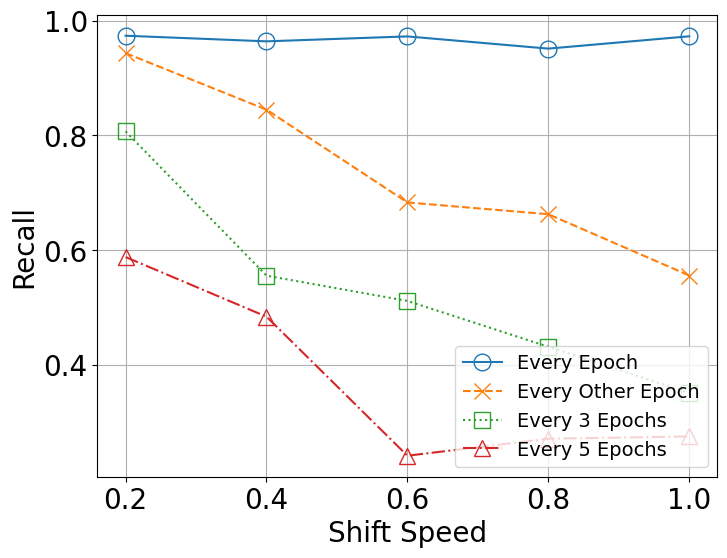
Recall: the figure shows the recall value for different scenarios without offloading samples to the ES. As seen in the figure, persistent updating of the model leads to high recall, which decreases if less frequent updating is used. This also leads to an increase in resource usage for the system. Furthermore, the results indicate that by increasing the shift speed, the recall decreases as well. Indeed, when the shift speed is low, the distribution of data does not change significantly, and thus, the current model provides good accuracy to the samples. On the other hand, increasing the shift speed leads to a momentous change in the distribution of the samples. As a result, the current model is not able to classify the samples accurately and a higher share is required to be offloaded to the ES. Hence, the offloading ratio increases.
Conclusion
In this paper, we proposed an online domain adaptive classification framework to perform a classification task leveraging the collaboration between an MD and the ES in a setting in which the distribution of the observed samples drifts over time. The proposed framework determines model updates and fine-grained offloading decisions. Simulation results implemented on both synthetic and real datasets reveal that the proposed framework can improve the accuracy of simple classifiers deployed at MDs while reducing resource usage. According to the results obtained from experiments, it is important to frequently update the model, possibly at every epoch, to get a satisfactory performance. However, this comes at a system cost, especially in terms of latency to receive the updated model.