
 IEEE
IEEE Web of Science
Web of ScienceK-Means Clustering
K-Means is an unsupervised learning algorithm that partitions data into \(K\) distinct clusters. The algorithm begins by initializing \(K\) cluster centers, known as centroids. Each data sample is then assigned to the nearest centroid (commonly based on Euclidean distance) after which the centroids are updated as the mean of all samples within each cluster. This process repeats iteratively until the centroids no longer change significantly or the maximum number of iterations is reached.
Implementation
The K-Means clustering model in Python was developed from scratch following the guidelines provided in [2]. The complete implementation script is available on K-Means Clustering from Scratch.
We developed a K-Means clustering model for the breast cancer dataset using the built-in functions provided in \textit{scikit-learn} in Python (we kept the target labels for evaluation purposes). The following screenshot illustrates the model's fitting and predicting process. The model was imported from sklearn.clusters. The complete implementation script is available on the GitHub page K-Means Clustering.
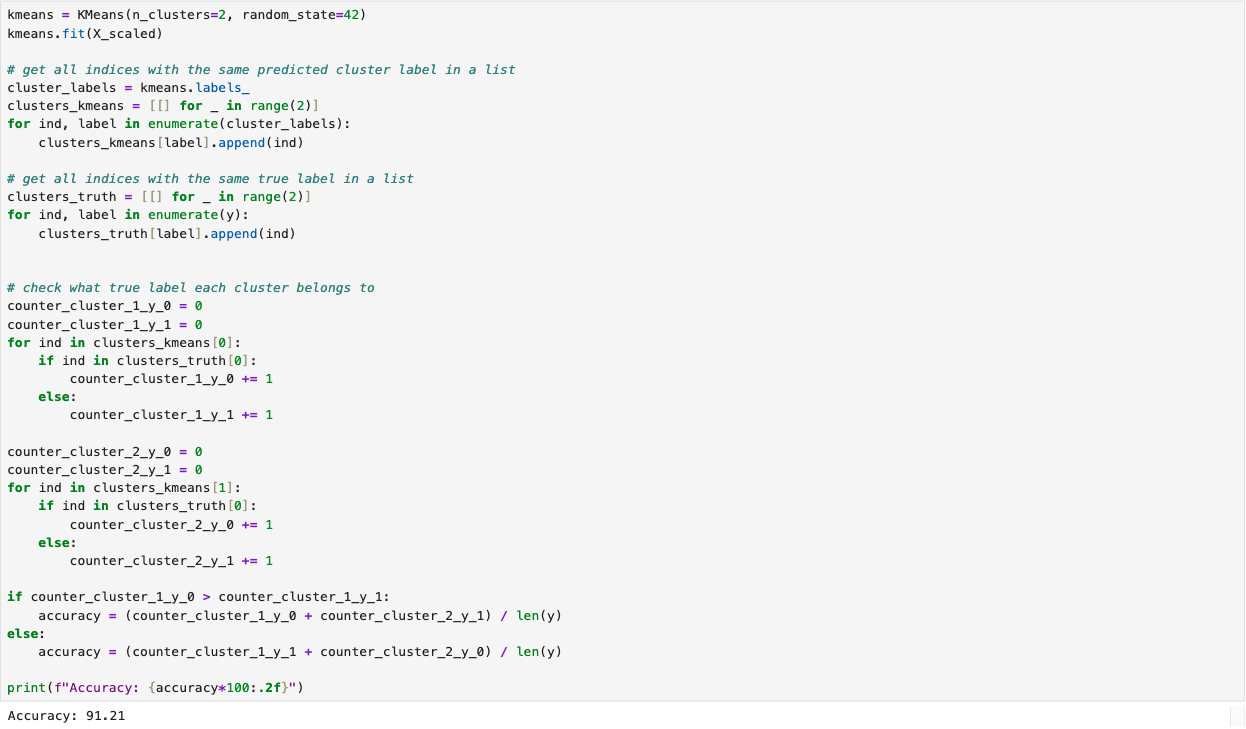
References
[1] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
[2] Patrick Loeber, “How to implement K-Means from scratch with Python,” AssemblyAI, accessed: September 21, 2022, https://www.youtube.com/watch?v=6UF5Ysk_2gk.