
 IEEE
IEEE Web of Science
Web of ScienceSupport Vector Machine
Support Vector Machine (SVM) is a linear model designed to find a decision
boundary (or hyperplane) that separates classes in the feature space.
The optimal hyperplane is the one that maximizes the margin, i.e.,
the distance between the hyperplane and the nearest points from each
class (also called support vectors), which typically leads to better
generalization and classification performance. Figure 1 illustrates
the SVM with linear kernel wherein the red line is the separator
surrounded by two dashed lines as the support vectors.
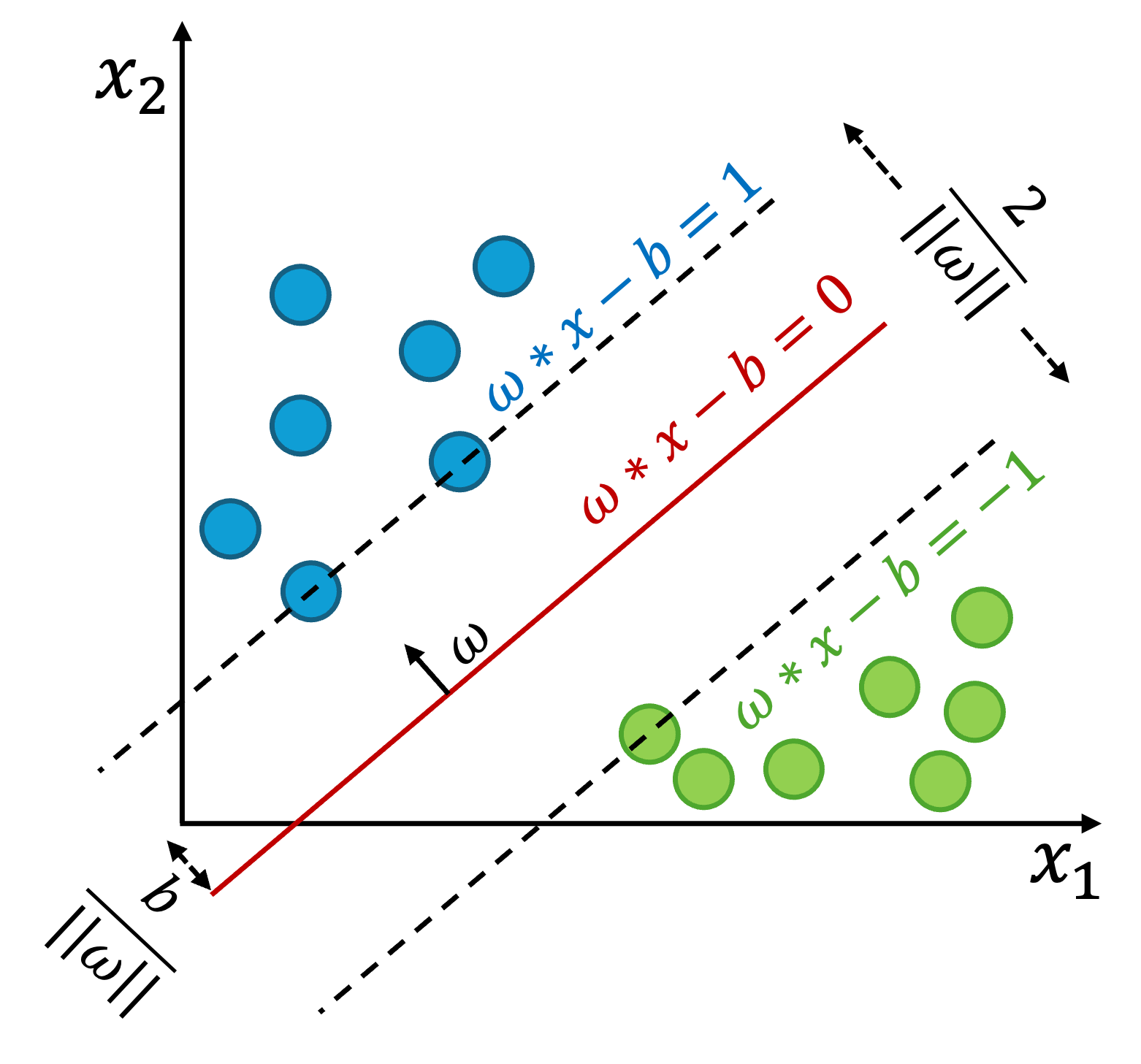
The linear hyperplane described above corresponds to the linear kernel in SVM, which produces a straight-line decision boundary suitable for linearly separable data. In addition to the linear kernel, SVM also supports non-linear kernels to capture more complex relationships. Two common non-linear kernels are the Radial Basis Function (RBF) and the Polynomial kernel. The RBF kernel generates a highly flexible, non-linear boundary capable of modeling intricate patterns, while the Polynomial kernel constructs non-linear boundaries using polynomial functions. However, the Polynomial kernel is more prone to overfitting when higher-degree polynomials are used.
The key hyperparameter in SVM is the regularization parameter, denoted by \(C\), which must be carefully tuned. The parameter \(C\) is a strictly positive value (commonly initialized as 1.0 by default) that controls the trade-off between maximizing the margin and minimizing classification error. Moreover, it is essential to normalize the input data in the preprocessing step for both training and testing. A commonly used normalization technique is z-score normalization, which standardizes features to have zero mean and unit variance.
Implementation
The machine learning SVM model in Python was developed from scratch following the guidelines provided in [2]. The complete implementation script is available on SVM from Scratch.
Classifier
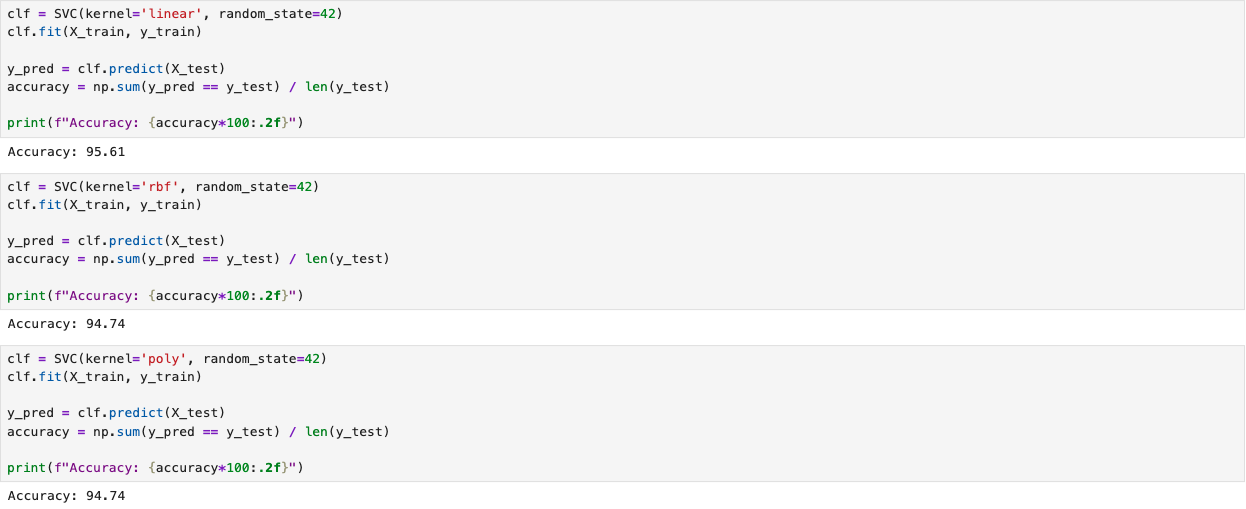
We developed an SVM classifier for the Breast Cancer dataset using the built-in functions provided in scikit-learn [1] in Python. The following screenshot illustrates the training process and the evaluation results of the model. The model was imported from sklearn.svm. The implementation includes all linear, rbf, and polynomial kernels. The complete implementation script is available on the GitHub page SVM Classifier.
Regressor
We developed an SVM regressor using the California Housing dataset available in scikit-learn. The following screenshot shows the training (fitting) process the regressor, following by the evaluation results. The implementation includes all linear, rbf, and polynomial kernels. The complete implementation script is available on the GitHub page SVM Regressor.

References
[1] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
[2] Patrick Loeber, “How to implement svm (support vector machine) from scratch with python,” AssemblyAI, accessed: September 20, 2022, https://www.youtube.com/watch?v=T9UcK-TxQGw.