
 IEEE
IEEE Web of Science
Web of ScienceRandom Forest
Random forest is an ensemble method that combines multiple decision trees, also known as a "forest", to make predictions. It employs a bootstrapping mechanism, also known as bagging, in which multiple subsets of the original dataset are generated by sampling with replacement. Each subset contains the same number of samples as the original dataset, but individual data points may appear more than once.
For each subset, a random subset of features is also selected, typically
with the number of features close to either \(\log_{2}M\) or \(\sqrt{M}\),
where \(M\) is the total number of features. A separate decision tree is
then trained on each bootstrapped dataset. Figure 1 illustrates an example
of bootstrapping and random feature selection for a dataset with four
samples and four features.

After training, the results from all trees are aggregated to produce the final prediction. For classification tasks, the ensemble uses majority voting, while for regression tasks, it computes the average of the individual tree predictions. Key characteristics of Random Forest include:
-
Since Random Forest employs both Bootstrapping and Aggregation, it is commonly referred to as a Bagging method.
-
The randomness in the algorithm originates from two sources: the random sampling of data points during bootstrapping and the random selection of features for each tree.
-
Random Forest is more robust and less prone to overfitting:
-
Bootstrapping alleviates overfitting by ensuring that each tree is trained on a different subset of data.
-
Random feature selection ensures diversity among trees by producing different decision boundaries. This reduces variance and helps prevent overfitting.
-
-
Compared to Gradient Boosting, Random Forest is faster to train and easier to tune, as its trees can be trained in parallel.
Implementation
The machine learning random forest model in Python was developed from scratch following the guidelines provided in [2]. The complete implementation script is available on Random Forest from Scratch.
Classifier
We developed a random forest classifier for the Breast Cancer dataset using the built-in functions provided in scikit-learn [1] in Python. The following screenshot illustrates the training process of the classifier. The model was imported from sklearn.ensemble. Moreover, we applied Grid Search Cross-Validation to identify the optimal hyperparameters of the model. In this process, we defined ranges for various various parameters, such as n_estimators (no. of trees), max_depth, min_samples_split, and min_samples_leaf.
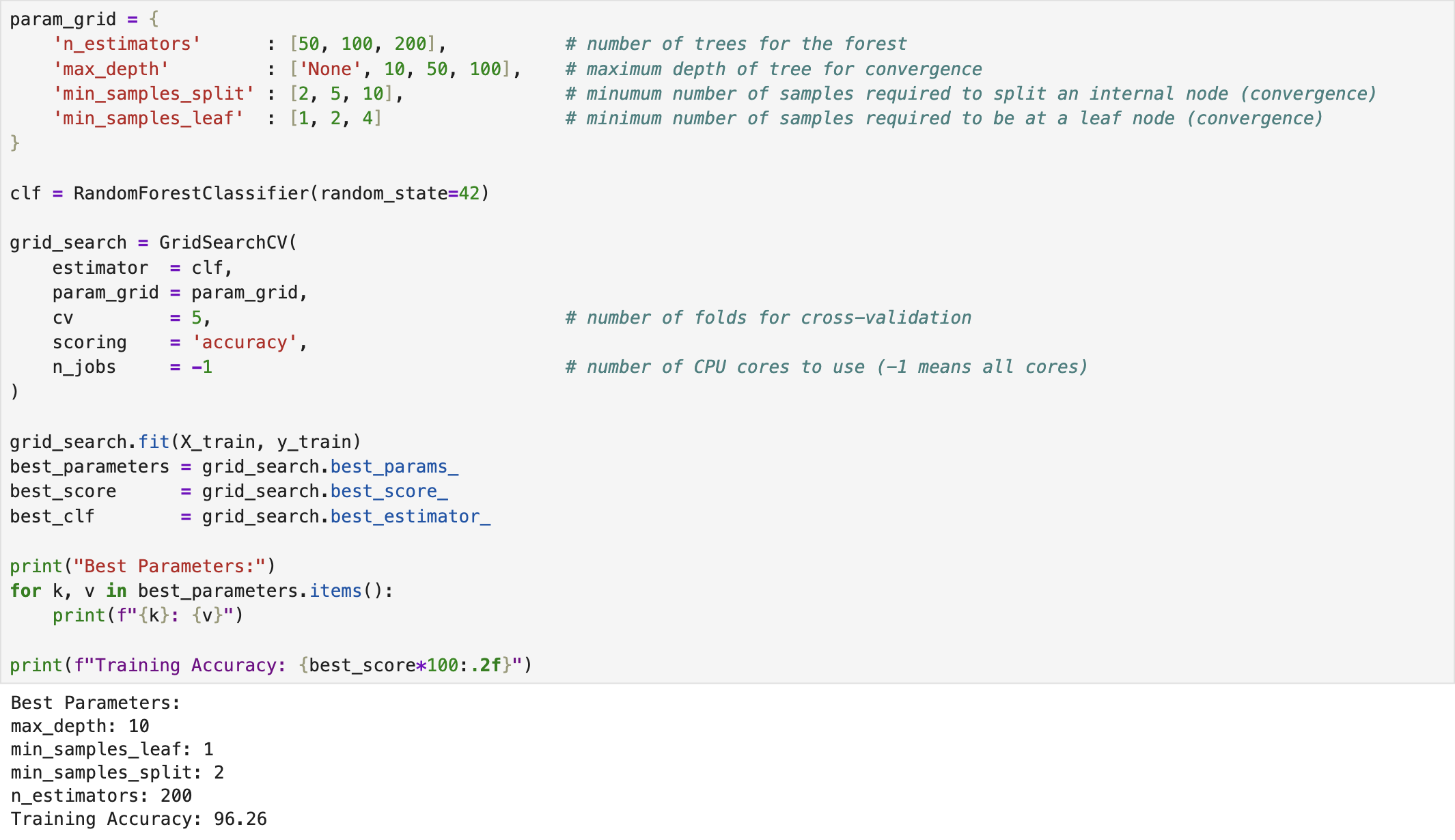
After identifying the best classifier through Grid Search Cross-Validation, we evaluated its performance using the test dataset. The following screenshot presents the corresponding results. The complete implementation script is available on the GitHub page Random Forest Classifier.

Regressor
We developed a random forest regressor using the California Housing dataset available in scikit-learn. The following screenshot shows the training (fitting) process of the regressor, where Grid Search Cross-Validation was employed to tune the optimal hyperparameters.
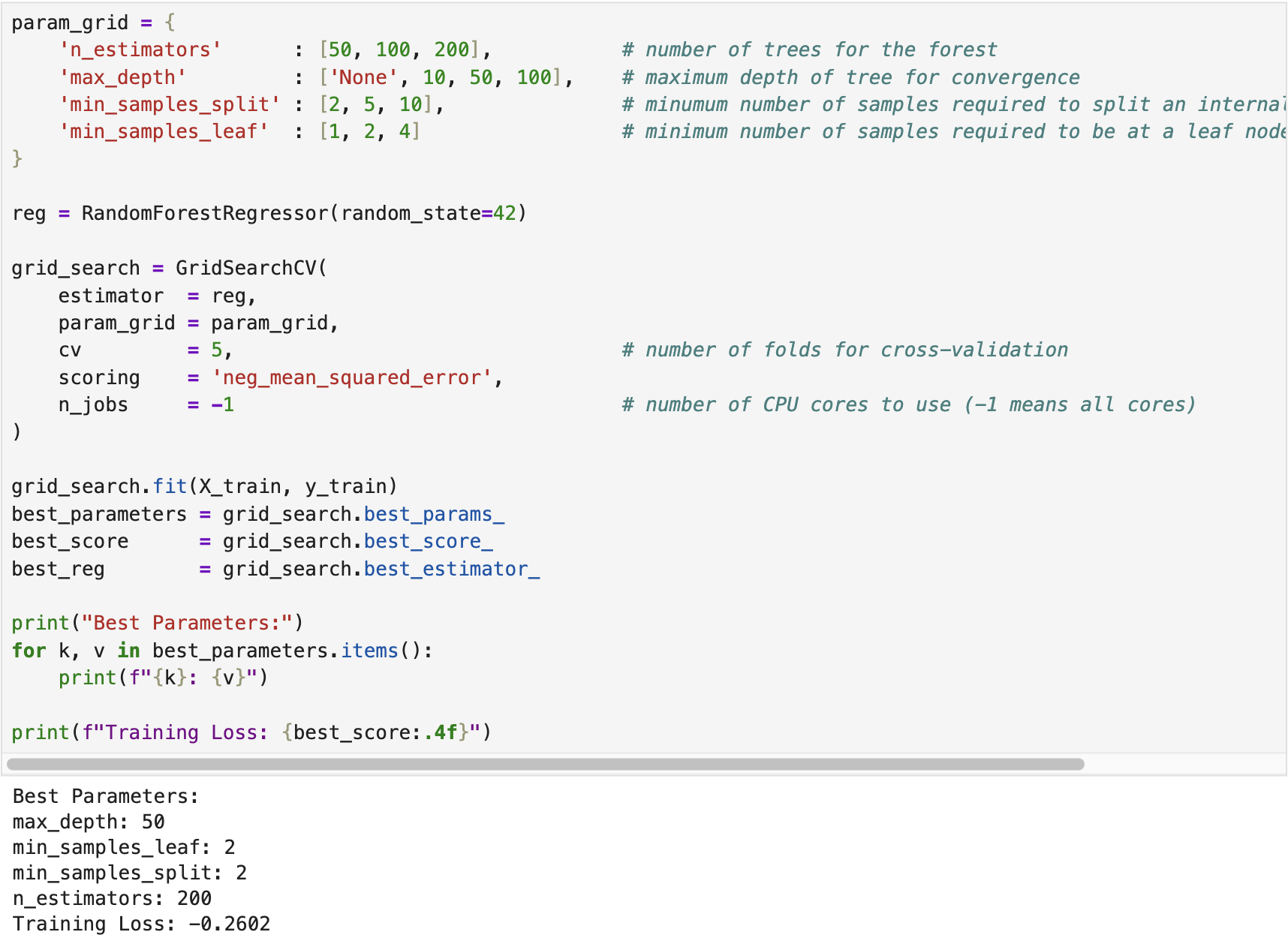
After training the regressor, we evaluated its performance on the test dataset. The following screenshot displays the corresponding results. The complete implementation script is available on the GitHub page Random Forest Regressor.

References
[1] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
[2] Misra Turp, “How to implement random forest from scratch with python,” AssemblyAI, accessed: September 16, 2022, https://www.youtube.com/watch?v=YYEJ_GUguHw.